pertrel地质建模-理论

[TOC]
地质建模软件初级培训
相关概念
什么是模型?
CT概念的导入
XY射线穿透人体对射线透射率不同,根本取决于密度。
可以逐层扫描,有一定厚度物体,最后形成三维模型。
要研究地下油气的分布,将油气开采出来,了解地层情况,搞清楚地下情况。
可以采用医学层面CT原理。
油藏地质模型(Reservior Geological Model)
油藏地质模型(Reservoir Geological Model)研究是20世纪80年代中后期兴起的一项用于油气藏描述和油气分布预测的复合学科理论和方法体系。它是集沉积学、储层地质学、构造地质学和石油地质学等地质理论,数学地质、地质统计学和油层物理学等方法为一体的,最大限度应用计算机技术进行油气藏及内部结构精细解剖,高度概括油气藏的类型、几何形态、规模、油藏内部结构、储层参数及流体分布的模型。

- 完整地质模型包括:
(1)构造模型:油藏构造形态及断层分布;
(2)储层地质模型:储层建筑结构及各种属性的空间分布;
(3)流体:储层内油气水分布,即各种流体饱和度分布和流体性质的空间变化。
油藏描述的最终归宿是建立油藏地质模型,而油藏地质模型的核心是储层地质模型,因此一般所说的地质模型均指储层地质模型。
储层地质模型
储层地质模型:定量反映储层地质特征及其分布的数字化模型。
通常是把储层网格化,给每个网格赋以各自的参数值,来反映储层参数的三维空间变化。网格的尺度愈小表明模型愈精细;每个网格的参数值与实际值误差愈小,模型的精度愈高。
储层地质建模的目的和作用
目的
地下储层是在三维空间分布的。
人们习惯于用二维图形(各种小层平面图、油层剖面图)及准三维图件(栅状图)来描述三维储层,如用平面渗透率等值线图来描述一套(或一层)储层的渗透率分布。
显然,这种描述存在一定的局限性,关键是掩盖了储层的层内非均质性乃至平面非均质性。
80年代以后,国外利用计算机技术,逐步发展出一套利用计算机存储和显示的三维储层模型,即把储层三维网块化(3D griding)后,对各个网块(grid)赋以各自的参数值,按三维空间分布位置存入计算机内,形成了三维数据体,这样就可以进行储层的三维显示,可以任意切片和切剖面(不同层位、不同方向剖面),以及进行各种运算和分析。通过精确地定量描述储层各项参数的三维空间分布,为油气田的总体勘探取向和开发中的油气藏工程数值模拟奠定坚实的基础。
三维储层建模不等同于仅仅是储层的三维图形显示。从本质上讲,三维储层建模是从三维的角度对储层进行定量的研究并建立其三维模型。
其核心是对井间储层进行多学科综合一体化、三维定量化及可视化的预测。
油藏地质模型的作用
-(1)为油藏数值模拟提供定量地质模型。油藏数值模拟成败的关键在很大程度上取决于三维地质模型的准确性。
-(2)更客观地描述并展现储层各种属性的空间分布,克服了用二维图件描述三维储层的局限性。有利于油藏工程师进行合理的油藏评价及开发管理。
-(3)将测井、构造、沉积、岩石物性等研究成果进行综合统一到一个完整的三维模型内,为进一步的地质研究提供依据和基础。
-(4)油藏开发到一定程度之后,剩余油的评价是一个很重要的课题。精细地质模型可以在微构造落实、单砂体横向追踪、储层单元三维空间展布研究等方面提供可靠的依据和成果。
-(5)可用于定量研究储层描述的不确定性,进而研究油气勘探和开发的不确定性和投资风险。
-(6)可更精确地计算油气储量。在常规的储量计算时,储量参数(含油面积、油层厚度、孔隙度、含油饱和度等)均用平均值来表示。显然,应用平均值计算储量忽视了储层非均质因素,例如,油层厚度在平面上并非等厚,孔隙度和含油饱和度在空间上也是变化的。

地质模型分类
不同学者研究地质体的层次不同,以及研究储层目标参数的着重点不同,因此就有不同的地质模型分类。

依据不同开发阶段的任务与要求(裘亦楠,1991)
概念模型
是指把所描述油藏的各种地质特征,特别是储层,典型化、概念化,抽象成具有代表性的地质模型。

概念模型只追求油藏(储层)总的地质特征和关键性地质特征的描述,基本符合实际,并不追求所有局部的客观描述。可供研究油田开发中的战略指导路线或开采机理。
静态模型
静态模型概念:是把一个具体研究对象(一个油田、开发区块或一套层系)的储层,依据资料控制点实测的数据将其储层特征在三维空间的变化和分布如实地描述出来而建立的地质模型。并不追求控制点间的预测精度。建立这样的地质模型一般是开发井网完成后进行才有条件,为油田开发早期生产服务。
建立方法:采用各种资料、用地质统计学的确定性建模方法来建立静态模型。
预测模型
预测模型概念:不仅要忠实于资料控制点的实测数据,还要对控制点间及以外地区的储层参数作一定精度的内插和外推,具预测功能的模型。
建立方法:主要是采用随机建模技术,即将等概率的随机抽样方法(蒙特卡洛)与确定性的插值方法(克里金)相结合,所形成的地质统计学随机算法,来产生多个高精度的随机实现图像(预测模型)。
依据储层属性及模型表述的内容
骨架模型
主要是用于反映储层的各向异性特征,即储集体(砂体)性质与几何形态的空间展布。
广义上储层骨架模型包括:沉积(相)模型、储集体(砂体)模型、流动单元模型及裂缝模型,其核心是它们均属于离散(变量)模型的范畴。

①沉积模型
沉积模型主要是展现储层形成的沉积相,尤其是微相在三维空间的分布。油田开发生产实践表明,沉积相带的分布特征强烈地影响着地下流体的流动。同时,岩石物性的变化明显地受相类型的控制。严格来讲,所有的油气储层都是由多种沉积微相组成的,因此,合理的相模型是精确建立参数模型(岩石物性模型)的必要前提。
②储集体(砂体)模型
尤其表现有效储集砂体与泥岩隔、夹层的三维空间分布特征。在必要的情况下也要建立隔、夹层连井剖面与模型,以此来验证砂体模型与地质认识的一致性。
结构模型:是指储层内部不同类型储集体的大小、几何形态及其三维空间的展布,就碎屑岩而言,它是砂体连通性及砂体与渗流屏障空间组合分布的表征。
③流动单元模型
流动单元模型是由许多流动单元块体镶嵌组合而成的模型,既反映了单元间岩石物性的差异和单元间边界,还突出地表现了同一流动单元内影响流体流动的物性参数的相似性。当储集(砂)体相对较为均质时(即不存在明显的隔、夹层时),砂体模型与流动单元模型十分近似,这时可将其作为流动单元模型。
④裂缝模型
裂缝分布模型可分为二类,其一为三维裂缝网络模型,表征裂缝类型、大小、形状、产状、切割关系及基质岩块特征等,其二为二维裂缝密度模型,表征裂缝的发育程度 。
参数模型
参数模型属于连续变量分布模型的范畴。包括孔隙度、渗透率及含油(或含水)饱和度模型。

依据研究储层的层次规模与维数
按储层的层次与规模划分
此类模型划分的思路主要是依据储层非均质性层次而进行的,熊琦华、王志章等(1990)依据中国陆相油田的地质特点,主要是借用国外(Pettijohn,1973)划分储层非均质的思路与方法,将储层地质模型划分为油藏规模、砂组规模、小层规模、单砂体规模、岩心规模及孔隙规模六个级别。
按研究的资料状况与维数
可划分为一维、二维及三维模型。
一维单井地质模型及一维层内非均质性模型;
二维砂体剖面、二维平面模型及二维层系剖面模型;
三维砂体骨架或参数模型,三维井组模型及三维夹层模型等。
依据研究的数据对象或变量特征
离散型(性)模型(Discrete Model)
主要用于描述具有离散性质(各向异性)的地质特征,即储层某一性质的几何特性在空间上的不均一性分布,如沉积相分布、砂体位置和大小、泥质隔、夹层的分布和大小、裂缝和断层的分布、大小、方位等。
连续型(性)模型(Continuous Model)
主要用于描述储层连续参数(变量)(非均质性)的空间分布,即储层的物理特性在空间上的不均一性分布,如孔隙度、渗透率、流体饱和度、地震层速度、泥质含量等参数的空间分布。
三维建模通用流程

数据准备→三维构造建模→三维相建模→三维储层参数建模→模型粗化→油藏数模
1.数据准备
从数据来源看,建模数据包括井数据、地震数据、动态数据、地质解释的二维剖面及平面研究成果和数据等。
井数据
井数据包括井基本信息、岩心数据、测井及其解释数据、分层数据、断点数据等。
①井基本信息
井名、井别、井口坐标、补心海拔、
完井深度及井深轨迹
②岩心数据
岩心数据包括岩心描述以及岩心分析数据。建模过程中,岩心数据主要作为测井数据的标定。
③测井及其解释数据
测井数据一般按每米8个数据点记录。测井数据文件格式种类较多,如716格式、Las格式等。
单井测井储层解释数据包括沉积相、储层参数等。其数据记录方式有两种:一是连续曲线格式;二是小层数据表格式,为砂层的平均数据。
④分层数据
分层数据包括地层分层及砂体分层。
⑤断点数据
断点为井轨迹与断层面的交点,其数据应包括井名称、断层名称、断点深度值等。
地震数据
地震数据包括地震解释的断层数据、层面数据以及从地震数据体中提取或特殊处理得到的地震属性数据等。
①地震解释的断层数据
地震解释的断层数据一般包括断层Stick和断层多边形( Fault polygon )。
断层Stick为地震剖面上解释的断层线,为一组顺断面的三维线条 。

Fault polygon为断层面与各构造层面的交线 。
②地震解释的层面数据
地震解释的层面数据为某一层面的地震解释线数据或网格数据,实际上往往是作为三维点数据输入。
③地震属性数据(软数据)
地震属性数据主要是可反映储层岩相及储层参数的各种地震属性数据体,如速度、波阻抗、振幅等。地震属性数据为储层建模的软数据,可作为沉积相、储层参数建模的趋势控制。
软数据:总体趋势吻合,地震属性。
硬数据:必须一模一样,平面二维数据。
动态数据
动态数据主要为单井测试及井间动态监测数据。
动态数据反映储层信息包括两个方面:一是储层连通性信息,可作为储层建模的硬数据;二是为储层参数数据,如井筒周围平均渗透率,可作为建模的软数据。
平面研究成果和数据
在三维建模前,先需对研究区进行二维剖面解释和二维平面研究,如沉积相、砂体厚度、孔隙度、渗透率、油气水分布等。这些地质研究既要以成果图表示,在建模过程中作为参考,还应表达为网格化数据体,用作三维建模的趋势约束。
2.数据集成及质量检查
数据集成是多学科综合一体化储层表征和建模的重要前提。集成各种不同比例尺、不同来源的数据(井数据、地震数据、试井数据、二维图形数据等),形成统一的储层建模数据库,以便于综合利用各种资料对储层进行一体化分析和建模。
为了提高储层建模精度,必须尽量保证用于建模的原始数据特别是硬数据的准确可靠性,而应用错误的原始数据进行建模不可能得到符合地质实际的储层模型。因此对不同来源的数据进行质量检查亦是储层建模的十分重要的环节。
3.网格设计
在建模过程中,合理的网格设计非常重要。如果三维模型的网块尺寸划分越小,标志着模型越细,其精度也越高,但是在实际应用中,网格大小的划分受计算机硬件和所建模型精度要求的制约。一方面,为了节省计算机资源,网格数目应尽可能少;另一方面,为了控制地质体的形态及保证建模精度,网格又不能过少。因此,应根据工区的实际地质情况及井网密度设计出合适的网格。
网格划分实例
根据工区内多数井距在1-2KM以上的实际情况,我们考虑将平面网格间距设计为100×100m,这样使得绝大多数井间具有10个以上网格;而在纵向上设计每0.5m一个网格,这样可以识别出厚度<1m的储层。因此,本次建模采用100×100×0.5m的网格系统,网格总数达到25622250个。

4.构造—地层建模
构造模型反映储层的空间格架。
因此,在建立储层属性的空间分布之前,应进行构造建模。构造模型由断层模型和层面模型组成。
根据地震解释和井资料校对的断层文件,建立断层的三维空间的分布。

层面模型为依据各井的层组划分对比数据及地震资料解释的层面数据而建立的地层界面三维分布,叠合的层面模型即为地层格架模型。
5.储层相模型
储层相模型为储层内部不同相类型的三维空间分布。实际上,三维相建模就是定量描述储集砂体的大小、几何形态及其三维空间的分布,即建立储层结构模型。 油田开发生产实践表明,相带分布强烈地影响地下流体的流动。同时,岩石物性的变化与相类型极为相关。对于多相分布的储层来说,合理的相模型是精确建立岩石物性模型的必要前提。
6.储层属性建模
储层属性模型的建立主要用于对连续储层变量的模拟。储层属性三维模型一般包括储层的孔隙度、渗透率及含油饱和度参数模型,储层三维地质建模的目的就是要获得储层物性的三维空间展布。
利用井数据或地震数据,按照一定的储层建模方法(插值或随机模拟)对每个三维网块进行赋值,建立储层属性(离散和连续属性)的三维数据体,即储层数值模型。

7.图形显示
数值模型→即三维数据体→图形显示
三维图形显示
任意旋转
不同方向切片
从不同角度显示储层的外部形态及其内部特点。
地质人员和油藏管理人员可据此三维图件进行三维储层非均质分析和进行油藏开发管理。
8.体积计算
根据三维储层模型进行油气储量计算。
- (1) 地层总体积
- (2) 储层总体积以及不同相(或流动单元)的体积
- (3) 储层孔隙体积及含烃孔隙体积
- (4) 油气体积及油气储量
- (5) 连通体积(连通的储层岩石体积、孔隙体积及油气储量)
- (6) 可采储量
9.模型粗化
目的:油藏数值模拟
计算机内存和速度的限制(常规的黑油模型网格节点数一般不超过百万个)。
模型粗化(Upscaling)是使细网格的精细地质模型“转化”为粗网格模型的过程,使等效粗网格模型能反映原模型的地质特征及流动响应。
软件简介
PETREL软件简介
所属公司:斯伦贝谢公司(Schlumberger)
平台:微机Windows
Petrel软件是一套目前国际上占主导地位的基于Windows平台的真正一体化油藏描述和三维可视化建模软件。它综合了地震资料解释、测井分析、地质综合研究、地质建模、数值模拟的一体化平台,适用于各种油藏类型。
利用多资料综合分析,可以精确描述油气藏及其孔渗饱等属性参数的空间分布,计算其储量、定量估算风险性、优选模型、设计井位和钻井轨迹、无缝集成生产数据和数值模拟器,发现隐蔽油气藏和剩余油气,从而降低开发成本,提高效益。
软件界面
Petrel 2009软件界面主要由
标题栏
菜单栏
工具栏
功能栏
Petrel浏览器
流程管理器
显示窗口


1)Petrel浏览器
Petrel浏览器也叫Petrel资源管理器,位于软件窗口左侧,用于优化各种模型关联数据的文件管理器。通过点击加号、减号可以打开和关闭文件夹。
Petrel浏览器包括四个选项卡:
Input(数据加载选项卡)
Models(模型选项卡)
Results(结果选项卡)
Templates(模版选项卡)



2)流程管理器
Petrel流程管理器包括四个选项卡:
Process(流程管理选项卡)
Cases(事件管理选项卡)
Workflows(过程管理选项卡)
Windows(窗口管理选项卡)


3)功能栏
为特定进程所具有的特定功能。这些工具会因为选择了不同的进程而改变,这些工具是否有效取决于选择进程表中的哪个进程。

4)显示窗口区
显示模型,图形的地方,可以显示不同类型的目标体。能同时打开任意多的窗口。
例如3D、2D窗口、井剖面窗口(井相关)、解释窗口(地震解释)。

软件主要功能系统
依据功能,Petrel软件可分为五大部分(系统):
- 一是
地震资料解释一体化系统; - 二是
综合地质分析系统; - 三是
三维地质建模系统; - 四是
井位设计及随钻跟踪系统; - 五是
油藏工程与模拟系统;
地震资料解释一体化系统
地震资料解释一体化系统可快速实现地震资料剖面解释和三维立体解释、实体建模、地震数据的叠后处理及属性提取、速度分析及时深转换、构造分析及断层自动提取、瞬层属性平面成图等,通过地震数据网格重采样建立地震实体模型,预测有利目标。
2D、3D地震资料综合解释(Seismic Interpretation)
- 完成多种数据类型的综合解释,强大的3D体可视化解释更精确识别各种地质现象,并实时提供强大的一体化质量控制功能;
- 强大灵活的3D同相轴自动追踪和断层解释,遇断层可自动终止;
- 2D测线管理及闭合差校正。

地震数据的叠后处理 (MultiTrace Attributes)
属性生成工具包囊括了GeoFrame地震属性软件包的所有可用属性。通过对地震数据体的叠后处理,研究人员可以获得更清晰的构造特征和地层特征,从而更充分地利用地震信息进行油藏分析。
地质体雕刻(Geobody Interpretation)
Petrel Geobody Interpretation模块用应用数据体合成的方式来从地震数据体中得到目标体。利用多个不同的属性可视化,用户可以合成一个特征体,并将其提取出来转换成离散目标体。提取的目标体叫”geobody”,geobody的提取本质上来说就是“所见即所得”。

地震数据时深转化与重采样(Seismic Depth Conversion & Sampling)
该模块可以根据时深转换的速度模型对地震数据体进行深度转换,把目的层段内的三维地震数据体转换到深度域,并与油藏模型的网格相匹配。
断裂系统自动分析 (Ant-Tracking)
在Petrel中,通过一种先进的算法Ant-Tracking而得到的一种全新的自动断层解释工作流程,克服了手工解释断层的主观性。在提高精度、地质细节和构造的认知程度及油藏认识的同时,大大地减少了常规解释的时间。
综合地质分析系统
Petrel为用户提供完整的地质基础研究一体化解决方案。可以进行测井解释、沉积微相划分、地层对比、储层四性关系研究等工作。用户可以在最短的时间内认识油藏,为高分辨率地质建模准备基础数据库。
- 属性(地震,测井)聚类分析和估算
- 地层对比
- 构造特征研究
- 储层特征研究
- 储层四性关系分析
- 数据分析
- 断层封堵性分析
- 表面成像
- 多媒体汇报系统及地质图件制作
属性(地震、测井)聚类分析和判断
聚类分析模块提供给用户进行神经网络分析的工具。当数据之间存在一个非线性的关系时,或者当无法得到单一或两个变量来提供一个合适的对比时,神经网络技术具有独特的优势。它能够使用户先培训然后再去建立评估的模型目标。
聚类分析和判断")
地层对比(Well Correlation)
可建立联井地质模型,进行地层对比、划分及储层解释;可显示合成地震记录、进行井曲线编辑;利用曲线的计算功能生成新的测井曲线;沿设计的井轨迹产生伪测井曲线。

地质成图及绘图(Mapping & Plotting)
可快速进行平面图、剖面图等图件的定比例绘图,图形可以通过拷贝、粘贴到Word、Excel、PowerPoint中。支持emf矢量图件直接输出。

体积计算 (VolumeCalculation)
烃类的体积计算可以根据层系、油水界面、实际生产数据等为条件。由于有精确的构造模型和准确的单元划分,提高了储量计算的精度。每个层系、每个断块都可以定义不同的油水面,既可以计算整个模型、也可以计算某个单独的断块或层系。
同时,可以利用蒙特卡洛法计算储量,生成储量分布曲线图,定量估算风险性。

断层封堵性分析
在体积上,断层虽然只占油藏的极小一部分,但断面的封堵性对整个油藏的渗透性、地下流体的流动特征具有巨大的影响。因此,断层封堵性的定量计算对油藏的产液特征的预测十分重要。Fault Analysis能依据Petrel建立的地质模型和统计数据,定量计算断面的传导率。模拟的属性结果可用于在ECLIPSE模拟器中计算断面传导率。

数据分析(Data Analysis)
数据分析工具可以更好地了解数据在空间分布的趋势和规律,也可以获得各种数据间的关系。
- 通过趋势分析和数据转换获得精确的模型
- 进行变差函数分析
- 快速产生交绘图和直方图
- 生成回归曲线和累计分布函数

三维地质建模系统
三维地质建模系统提供了完整的地质建模一体化解决方案,基于目标和基于象元的随机模拟组合技术帮助用户建立高精度的三维地质模型,掌握、跟踪及更新日益完善的油藏模型,无缝整合油藏模拟环境,过程管理模块使用户快速更新模型,减少研究周期。
- 地层格架模型建立
- 相建模
- 油藏属性建模
- 裂缝建模
- 储量计算
- 模型粗化
相建模 (Facies Modeling)
Petrel 提供了序贯指示模拟、截断高斯模拟、神经网络方法、基于目标的示性点模拟、多点地质统计学等几种用于表征相带分布特征的确定性和随机性相建模技术,而且可以交互使用。同时用户可以导入自己的算法和人工赋值的方法,建立沉积相模型。独有的河流相建模算法为建立河流环境和浊积环境下的沉积相模型提供了半随机技术,用户可以描述出各沉积时期相带的空间分布,分析沉积演化史。

裂缝建模(Fracture Modeling)
Petrel裂缝建模是基于地质概念、充分利用断层和成像测井的裂缝知识、通过类比野外露头建立的裂缝概念模型、可预测裂缝成因的地震属性等各种资料,并将这些资料转换成裂缝强度等参数,建立三维的离散的裂缝网络模型。
离散裂缝网络模型直接用裂缝片来描述裂缝系统,因此解决了传统的裂缝建模方法所遇到的各种困难。

油藏属性建模 (Petrophysical Modeling)
这是一个将三维网格中的每个单元赋予属性值的过程,利用测井数据、钻井数据和各属性层面趋势图,采用序贯高斯模拟的算法进行工区内的确定性和随机性属性建模。随机建模可以采用岩相模型、地震属性模型等作为属性模拟的约束条件。
确定性建模算法
克里金方法
滑动平均法
函数法
近点距离
赋值方法
神经网络随机建模算法
序贯高斯模拟
高斯随机函数模拟
克里金算法(插值)
GSLIB克里金算法
井位设计及随钻跟踪系统
在3D环境中,依据所获得的信息,如构造,储层特征、岩相划分及油藏模拟等结果,直接提出井位部署方案,产生井轨迹坐标,指导钻井生产。同时可对设计井轨迹和实钻井轨迹、井曲线进行可视化显示,建立随钻模型。
主要特征:
- 根据地震剖面、属性模型、储量丰度平面图或数模结果进行快速3D井轨迹设计;
- 对于超过狗腿度值的井轨迹进行突出显示;
- 产生井轨迹报告和预测测井曲线;
- 输出井轨迹报告,以用于钻井工程和流体模拟的需要。
油藏工程与模拟系统
该系统工具箱中包括油藏工程核心系统、流线模拟、井位设计、油藏模型网格设计及高级粗化、生产历史拟合分析模块,帮助用户根据生产历史优选地质模型。同时灵活的滤波和可视化功能更加清晰有效的突出油藏模型的特征。
核心模块-Advanced core
流线模拟-FrontSim locked
历史拟合-History Match Analysis
油藏模型粗化-Advanced gridding and upscaling
井位设计-Well Design

软件特色
1)贯穿整个油藏描述的协同工作环境
综合了地球物理、测井、岩矿分析、地质统计、数值模拟等多种学科的一体化平台,贯穿整个油藏描述过程。
2)集成化数据管理平台
全面支持石油行业主流软件格式,具有很强的数据输入输出能力。
3)软件界面友好,易学习和使用
4)快速、准确的模型更新能力
5)在所有建模软件中,Petrel具有很快的运算速度和较好的性能
6)方便的多媒体、报告制作能力
数据输入
数据准备
wellheader(井头文件)
wellheader井头文件,包括
①井名,Wellname;
②x坐标,X-coord;
③y坐标,Y-coord;
④井底深度,KB;
⑤补心海拔,Td(MD);
⑥井别(油井,气井,注水井等用户可以自己定义),Symbol。
其中WellName(井名)是必须的且井名必须唯一,X、Y坐标也是必须的,其余为可选项。
| Wellname | X-coord | Y-coord | KB | Td(MD) | Symbol | 备注 |
|---|---|---|---|---|---|---|
| X1 | 239749.5300 | 4581430.2300 | 944.87 | 5754.00 | 2 | 干井 |
| X2 | 245019.6500 | 4582221.3600 | 942.11 | 5370.00 | 3 | 油井 |
| X3 | 246821.7400 | 4582047.7900 | 941.32 | 5750.00 | 4 | 低产油井 |
| X4 | 244804.0900 | 4583215.8600 | 941.98 | 5580.00 | 3 | 油井 |
| X5 | 243662.9300 | 4584608.3500 | 942.70 | 5602.00 | 3 | 油井 |
| X6 | 243397.0300 | 4580738.9900 | 944.42 | 5633.65 | 3 | 油井 |
| X7 | 241839.9400 | 4582251.2300 | 937.55 | 5620.00 | 15 | 注水井 |
| X8 | 15241839.9400 | 4582251.2300 | 937.55 | 5826.00 | 19 | 报废井 |
每列的位置比较自由,没有固定的顺序。
井斜(井轨迹)数据文件
井轨迹数据应该是ASCII码文件,按列排放。数据中包含几种可能的信息组合格式:
- ①Measured depth(测深MD),inclination(井斜角),azimuth(方位角);
| MD | AZIM | INCL |
|---|---|---|
| 1499.88 | 99.85 | 42.28 |
| 1500.03 | 99.85 | 42.28 |
| 1500.18 | 99.85 | 42.28 |
| 1500.34 | 99.85 | 42.28 |
| 1500.49 | 99.85 | 42.29 |
| 1500.64 | 99.85 | 42.29 |
| 1500.79 | 99.85 | 42.29 |
- ②True vertical depth(真垂深TVD), X-offset(X偏移量), Y-offset(Y偏移量) (MD可选) ;
| MD(米) | TVD(米) | DX(米) | DY(米) |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0.125 | 0.125 | -0.001 | -0.004 |
| 0.25 | 0.25 | -0.002 | -0.007 |
| 0.375 | 0.375 | -0.004 | -0.011 |
| 0.5 | 0.5 | -0.005 | -0.014 |
- ③True vertical depth(真垂深), X, Y (MD可选)
| MD(米) | TVD(米) | X坐标(米) | Y坐标(米) |
|---|---|---|---|
| 0 | 0 | 15703611.07 | 4149596.08 |
| 0.125 | 0.125 | 15703611.07 | 4149596.083 |
| 0.25 | 0.25 | 15703611.07 | 4149596.086 |
| 0.375 | 0.375 | 15703611.07 | 4149596.089 |
| 0.5 | 0.5 | 15703611.07 | 4149596.092 |
| 0.625 | 0.625 | 15703611.08 | 4149596.094 |
测井数据文件
Petrel软件对输入的测井曲线格式是灵活的,唯一的要求是测井数据文件按列排列,即每条测井曲线为列数据排列。
Petrel软件支持LAS格式和文本格式的测井曲线数据。
- 文本格式
| DEPTH | AC | CNL | DEN | GR |
|---|---|---|---|---|
| 5180 | 49.091 | -0.2 | 2.745 | 33.432 |
| 5180.125 | 49.373 | -0.2 | 2.741 | 33.375 |
| 5180.25 | 49.395 | -0.2 | 2.74 | 32.041 |
| 5180.375 | 49.241 | -0.1 | 2.743 | 32.195 |
| 5180.5 | 48.854 | -0.1 | 2.746 | 31.385 |
| 5180.625 | 48.325 | 0 | 2.749 | 33.124 |
- LAS格式

加载工区边界

需要对工区数据进行数值化。
地质分层数据
分层数据是指一个层位或者一个断层与井轨迹发生交叉,在井上的一系列标记。
| MD | Type | Horizon Name | Well Name |
|---|---|---|---|
| 2068.47 | HORIZON | Base Cretaceous | B4 |
| 1886.76 | HORIZON | Base Cretaceous | B8 |
| 1836.97 | HORIZON | Base Cretaceous | B9 |
| 2003.34 | HORIZON | Base Cretaceous | C1 |
| 1998.97 | HORIZON | Base Cretaceous | C2 |
| 2004.29 | HORIZON | Base Cretaceous | C3 |
| 1980.43 | HORIZON | Base Cretaceous | C4 |
创建工区
通过选择菜单栏的 File: Save Project ,Ctrl+S 或者单击Tools Bar上面的 Save Project 图标存储当前工区,软件会弹出“Save project as”窗口,提示输入工区名字,输入工区名称(如下图),OK。

裂缝建模
离散裂缝网络模型建立
DFN模型是目前世界上描述裂缝的一项先进技术,它通过展布于三维空间中的各类裂缝片组成的裂缝网络集团来构建整体的裂缝模型,实现了对裂缝系统从几何形态直到其渗流行为的逼真细致的有效描述。

裂缝建模思路
大尺度裂缝建模
通常这些都是些由地震资料确定大的断层和裂缝,它们的位置和形态基本上都是确定的。
小尺度裂缝建模
可优选地震属性体、基质模型等作为约束条件,采用地质统计学方法(随机模拟)预测裂缝空间分布,使之满足各种先验统计和认识。
断层形成
理论研究和实际观测结果表明,断层和裂缝的形成机理是一致的。
断层的形成可分为三个阶段:
第一个阶段是大量的微裂缝形成;
第二个阶段是由于微裂缝的形成而使岩石的坚固性下降,导致应力集中,许多微裂缝合并而成为大裂缝;
第三个阶段是大裂缝形成断层。
断层实际上是裂缝的宏观表现,裂缝是断层形成的雏形。
一般来说,在已存在的断层附近,总有裂缝与其伴生,两者发育的应力场是一致的。
由于地震资料含有丰富的构造信息,因此,地震在裂缝描述中具有非常明显的作用,特别是对大裂缝及中等裂缝的描述。
大尺度裂缝分布模型
由于地震资料含有丰富的构造信息,因此,地震在裂缝描述中具有非常明显的作用,特别是对大尺度裂缝的描述。

应用已有的相干属性,采用 “蚂蚁追踪”算法,通过智能搜索功能和三维可视化技术,自动追踪和解释断裂面,得到蚂蚁追踪属性体 。
Ant-Tracking—蚂蚁追踪《Oil&Gas Journal》2007年“最佳勘探技术奖”
蚂蚁追踪原理
蚂蚁追踪技术是petrel软件提供的一种技术,应该是蚁群算法在地震资料中的应用,petrel软件未给出具体算法,只说是一种专利算法。其主要思想是模拟蚁群觅食的原理,在地震数据体中播撒大量的蚂蚁,在地震属性体中发现满足预设断裂条件的断裂痕迹的蚂蚁将“释放”某种信号,召集其他区域的蚂蚁集中在该断裂处对其进行追踪,而对于地震数据中不满足预测条件的地方则不追踪标记,最终得到一个蚂蚁体。因此,这项技术主要用来进行断层或裂缝的识别。
蚂蚁体追踪技术的技术优势
蚂蚁体追踪技术克服了传统地震解释的主观性。把解释集中在构造地质认识上而不是常规的拾取,在提高精度、地质细节和构造的认知程度及油藏认识的同时,大大地减少了常规解释的时间和局限性。
由于三维地震体纵横向信息的丰富性,保证了蚂蚁体追踪技术对井间裂缝和垂向裂缝描述的准确性,在裂缝空间分布规律的描述上具有显著的优势。
Petrel由于有速度转换等模块,很容易实现蚂蚁体裂缝信息从时间域到深度域的转换。
蚂蚁体追踪技术在断裂系统解释上,可以分为两种尺度来进行,一种是针对大断层的解释方案,另一种是针对裂缝系统的解释方案,通过该技术可以解释大量的裂缝信息,而不仅仅是断层信息。
蚂蚁体追踪技术工作流程
第一步骤是要求地震在信号领域压制噪声以达到其基本条件。
第二步是在地震数据上强化空间不连续性判别(断层属性提取,边界探测)。
第三步骤通过压制噪声和剔除非断层因素波动算法生成的蚂蚁追踪体更进一步明显突出断层特征。

首先对原始地震数据体进行信号分析及处理,产生 Structural Smoothing 属性体。目的是增加反射轴的连续性,突出断点反射。
在 Structural Smoothing 属性基础上,计算Variance 属性体,寻找边界异常。
在 Variance 属性体基础上,进行蚂蚁体追踪。

蚂蚁体追踪技术参数设定
定义种子点(Initial ant boundar)

即定义初始的蚂蚁分布边界,一个蚂蚁在一次觅食中所能涉及到的范围,并用以控制蚂蚁的分布密度,单位为voxel(地震面元)。
定义觅食路线的偏移度

限定种子蚂蚁在觅食中,其扫描觅食方向的范围,规定蚂蚁在15度的扫描范围内搜寻食物,搜到食物,释放信息,继续搜索。如果食物所在的位置超出该蚂蚁的搜寻范围,那么这个蚂蚁就不能追踪这个食物。一般定义参数范围0-3,数字越大代表搜索范围越大。
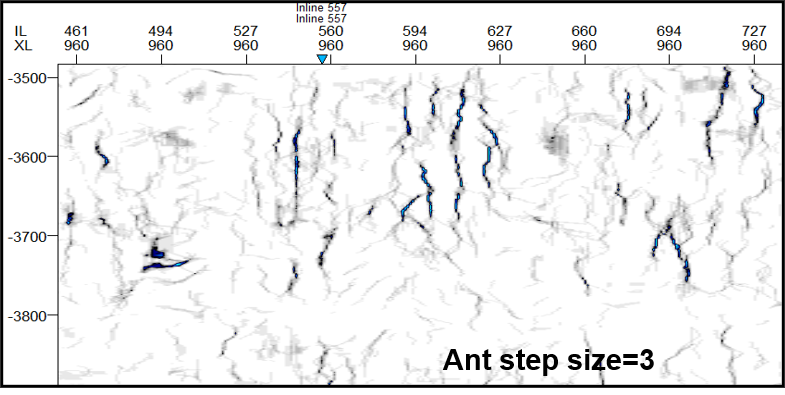
定义蚂蚁搜索的步长(Ant step size)

定义蚂蚁搜索的步长,单位Voxel。即蚂蚁在觅食过程中,一次能搜索的最大范围(几个地震网格)。

定义非合法规定范围(Illegal steps allowed)

规定一个蚂蚁在没有发现食物的情况下的最大搜索范围。在设定 Illegal Steps 为1的前提下,如果一个蚂蚁在当前位置上有食物,再向前一个Step时没有食物,这个Step就是Illegal Steps,如果再向前一个Step,仍没有食物,就产生连续两个Illegal Steps,这时这个蚂蚁就停止了搜索,被淘汰出局。如下图定义Illegal Steps 为2,那么连续两个Illegal Steps 后,出现食物,则蚂蚁可以继续搜索。参数定义范围0-3,数字越大代表搜索范围越大。
定义合法规定范围(Legal Steps)

合并非法蚂蚁步的参数,必须确保非法步后的合法步存在。如下图一个蚂蚁前进并发现食物,则标记为1 个Legal Step,继续前进并发现食物,则标记为第二个Legal Step,这时如果我们定义的Legal Steps 是2,那么这个蚂蚁的搜索路线就是有效的,并被记录下来。如果定义的是3,而蚂蚁前进至第三个Step 时没有发现食物,则这个蚂蚁的搜索路线就是无效的。参数设置范围0-3,越小连续性越好。
定义搜索终止的门槛值(Stop Criteria)

定义搜索终止的门槛值,也是非法步总数的参数,判断蚂蚁有多少非法步时终止探索的参数。给的数据为百分比,此参数越大蚂蚁的探索能力越强。
蚂蚁追踪处理结果
在蚂蚁追踪数据体的基础上,利用软件完成断裂面的自动追踪和提取。
断裂以北东向、北西向、近东西向及近南北向四组优势方向成带发育,裂缝以高角度和垂直缝为主。与区域地质认识一致。

小尺度裂缝分布模型
小尺度裂缝模型以成像等井筒资料为主
成像资料的处理
由于收集到的成像资料是 图片,因此需对相关数据进行读取和数字化。
成像测井裂缝密度数字化
裂缝定量计算图上的FVDC曲线为:校正后的裂缝密度,即为每m井段所见到的裂缝总条数。
通过对该曲线数字化,得到5口成像测井的裂缝密度数据。

成像测井裂缝产状统计

根据成像裂缝产状数据的统计分析,该区奥陶系储层裂缝以高角度裂缝为主(平均倾角77°)。

裂缝主要发育方位为北东向。其次为南北向,少量北西向裂缝。

裂缝密度曲线估算
采用人工神经网络计算其它井的裂缝密度曲线。以成像测井解释井作为网络训练数据,网络输入数据为自然伽马、声波时差、深浅侧向电阻率及其幅度差、密度。
对非线性数据建立预测数据,别的井输入之后就可以得到预测曲线。
- 神经网络裂缝密度训练相关系数表
| GR | DT | RD | RS | DEN | RD-RS | FVDC | |
|---|---|---|---|---|---|---|---|
| GR | 1 | 0.5743 | 0.579 | 0.5365 | 0.7893 | 0.5658 | 0.1114 |
| DT | 0.5743 | 1 | 0.5625 | 0.5697 | 0.563 | 0.3968 | 0.1603 |
| RD | 0.579 | 0.5625 | 1 | 0.9918 | 0.6671 | 0.7536 | 0.2009 |
| RS | 0.5365 | 0.5697 | 0.9918 | 1 | 0.6128 | 0.6785 | 0.2805 |
| DEN | 0.7839 | 0.563 | 0.6671 | 0.6128 | 1 | 0.7698 | 0.165 |
| RD-RS | 0.5658 | 0.3968 | 0.7536 | 0.6785 | 0.7698 | 1 | 0.1411 |
| TOTAL | 0.827 | 0.6972 | 0.9982 | 0.9977 | 0.8837 | 0.9389 | 0.6931 |


裂缝密度曲线模型
应用蚂蚁追踪数据体作为约束条件,采用协序贯高斯方法建立裂缝密度模型。


建立小尺度裂缝网络模型
以裂缝密度为约束条件,采用基于目标的模拟算法模拟了不同方向的多组小尺度裂缝。









小尺度裂缝模拟结果其倾角以高角度裂缝为主,与实际资料吻合。
小尺度裂缝的发育受断裂的控制,分布在断裂发育的附近。


裂缝系统等效参数计算
裂缝张开度
采用与裂缝尺度相关的经验公式,一般裂缝的开度与裂缝尺度成正比,根据成像解释成果的统计值确定各方位裂缝的比例系数,得到最终各组裂缝的开度计算公式:
- 北西向:
- 北东向:
- 南北向:
裂缝传导率
根据开度相关经验公式计算裂缝传导率
裂缝等效网格参数计算
根据裂缝网络模型中的裂缝连通关系及各组裂缝的传导率应用张量算法计算裂缝系统的各项异性渗透率 。


